Top 25 turfgrass tweets of the 2018 Ryder Cup
I did this analysis in 2016 and repeated it in 2018.
I figure that tweets by the golf course superintendent, Alejandro Reyes (@Reyes_golf), or tweets that mention the golf course superintendent, must be about the course maintenance. That’s what I’m calling “turfgrass tweets.”
Leading up to, during, and then immediately after the Ryder Cup, there were a lot of mentions of @Reyes_golf.
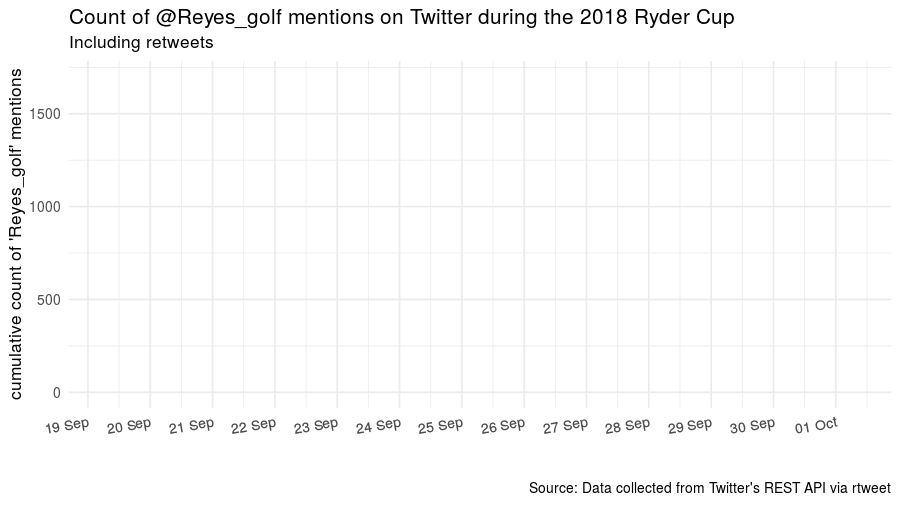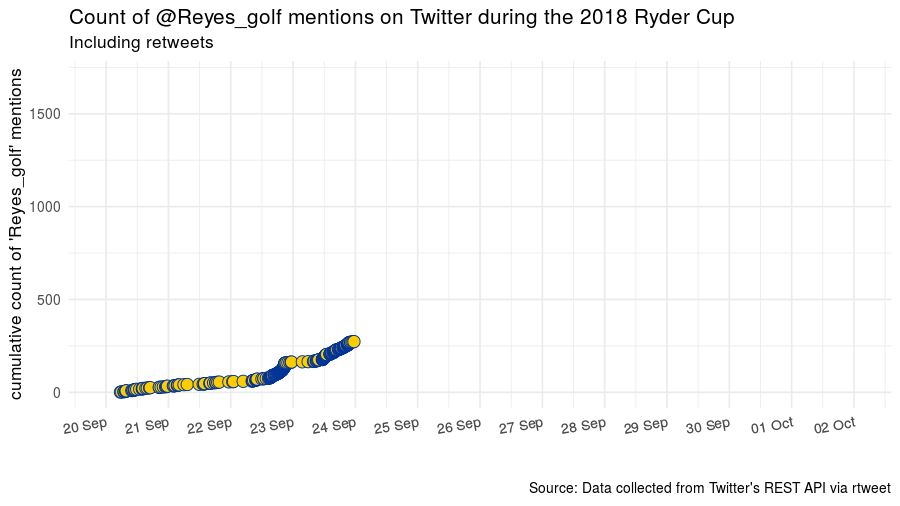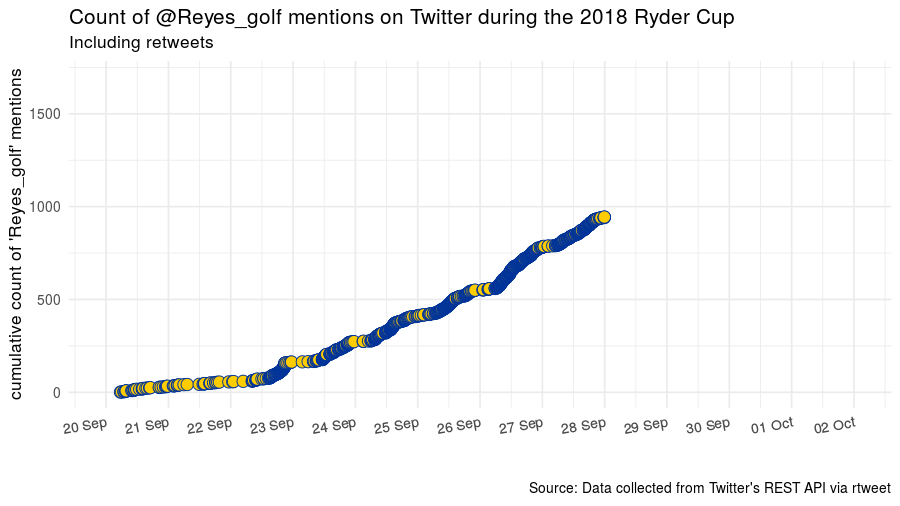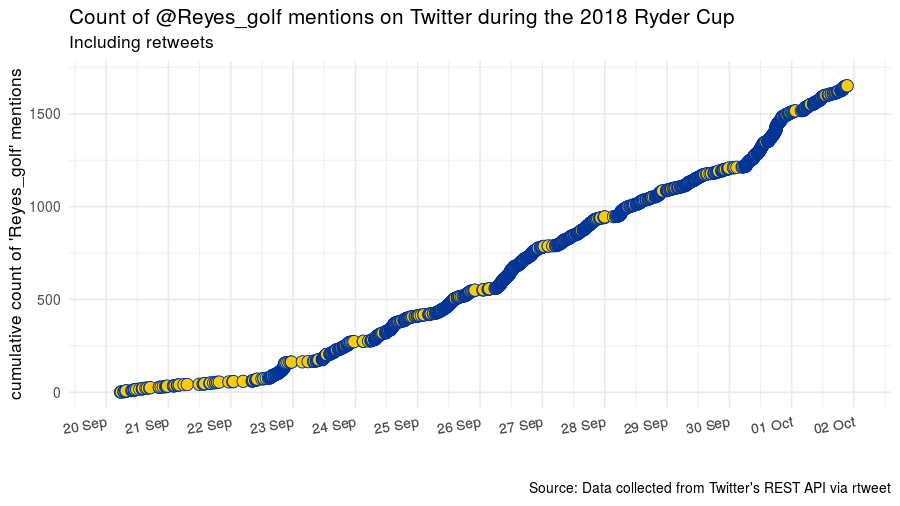
Using the excellent rtweet package, I found the favorite counts for each of those tweets that were returned in a search for Reyes_golf. The 25 tweets with the most favorites at the time of the search in October 2018 are what I am calling the top 25 turfgrass tweets.
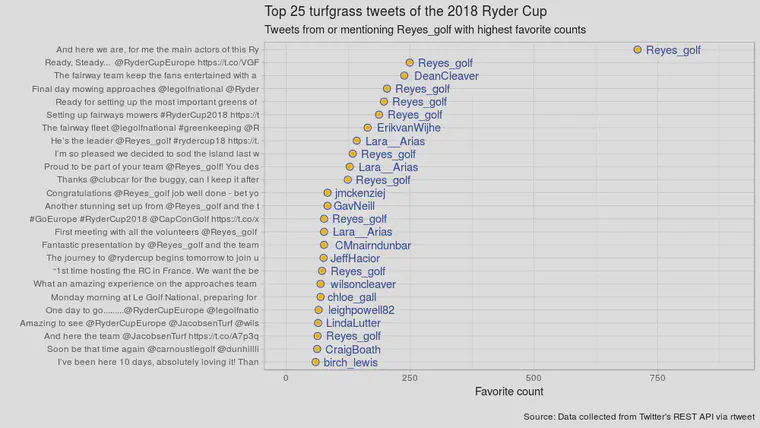
If I’ve missed any, please let me know. Further notes about that at the bottom of this post.
These tweets are gathered in chronological order in this Twitter Moment.
Top 25 turfgrass tweets of the 2018 Ryder Cup
Regarding possibly missing some tweets, I made a mistake when saving the tweets returned by the search during the Ryder Cup. When searching for a term or hashtag or user using the REST API, tweets from approximately the past 10 days are returned. Tweets from 20 or 30 days ago? Those won’t be returned by the search. I knew that, so I searched for the tweets and saved them during and in the week after the Ryder Cup. “I’ll get back to this, to sort them by favorite count, in a few weeks when I have time,” I thought.
But when saving the tweets—a tremendous amount of data is returned for each one, more than 50 columns of data—I cut the files to only the first 10 columns for convenience. In so doing, I removed the favorite count data, which was in like the 13th or 14th column. What I saved was the tweet ID and the text of the tweet and when the tweet was sent, but it was missing the favorite count.
Yesterday, when I finally had time to do this analysis, I realized the mistake I’d made. Fortunately, I had the status IDs for each tweet, and I had a vector for the 1,748 unique tweets during the Ryder Cup time period that included “Reyes_golf.” I used the lookup_statuses function from the rtweet package to get those tweets with full information including the favorite counts.
But the part I don’t understand is that recovered 1,131 tweets, but I had requested information on 1,748 unique tweets. If I’m lucky, then these 1,131 tweets that were returned are those that have the most interaction and the highest favorite counts. But it might be that I missed some.