I'd be applying potassium all the time
When I saw this photo captioned “a little potassium replenishment being applied,” I asked “replenishment from what loss?” As I found out, the potassium (K) was being applied after a heavy rain event.
I don’t think it is necessary to apply K after a heavy rainfall. Potassium fertilization can be made a lot simpler by ensuring the grass is supplied with enough K to meet all the grass requirements, and to ensure the soil stays above the MLSN guideline. The approach I advocate will ensure the grass has more than enough K, and will avoid unnecessary K applications.
I started writing a blog post about this, and mentioned to a superintendent what I was writing about—adding K every time it rains more than 25 mm (1 inch). “If I did that, I’d be applying potassium all the time,” he said.
Rain doesn’t change the grass requirement for potassium (K). I’ll start by making a generous estimate of how much K the grass may use in a year. I’m going to compare two grasses at two locations—creeping bentgrass in Minneapolis, Minnesota; and korai (Zoysia matrella) in Fukuoka, Japan.
Based on the average temperatures in Minneapolis, I estimate that a creeping bentgrass putting green, at the growth rates usual for this era, may use about 13 g N m-2 yr-1 (2.6 lbs N/1000 ft2/year). The K use of bentgrass is half the nitrogen use, so if the grass uses that much N, the K use (requirement) would be about 6.5 g K m-2 yr-1 (1.3 lbs K/1000 ft2/year). I don’t think this is necessary, but for the purpose of these calculations I’ll go ahead and round up the expected K use to 10 g and 2 pounds, just to make sure the grass gets supplied with a little more K than it will use. For every 1 gram of N I apply (or every 1 pound of N), I can apply 0.8 grams (or 0.8 pounds) of K. I would want to make sure the soil is above the MLSN guideline for K (37 ppm) and otherwise I can disregard the soil, because that fertilizer ratio will be supplying more K than the grass can use.
Making these calculations for korai in Fukuoka, the N estimate is 11 g N m-2 yr-1 (2.2 lbs N/1000 ft2/year). Korai uses N and K in about a 3:2 ratio, so the estimate of the K requirement for korai in that climate is 7.3 g K m-2 yr-1 (1.5 lbs K/1000 ft2/year). I’ll round this up to the same annual overestimate as at Minneapolis—10 g or 2 pounds.
At both locations, I’m estimating that turf maintained as a putting green will use slightly less than 10 g K m-2 yr-1 (2 lbs K/1000 ft2/year), so applying that much K will be supplying more than the grass will use. Whether it rains 25 mm (1 inch) or not, that rain is not changing how much K the grass will use. And I’m planning to supply that K whether it rains or not.
So what happens if I add in “potassium replenishment” after every day with precipitation greater than 25 mm at these two locations? I looked up the rainfall for Minneapolis (at the MSP airport station) and for Fukuoka from 1 January 2011 through 4 October 2015, and I counted up the number of days with precipitation greater than 25 mm.
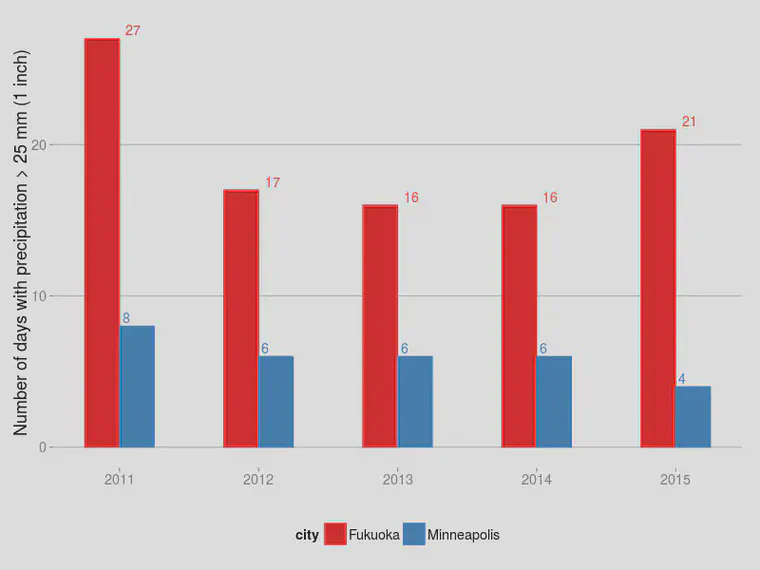
Averaged over the past five years, that is 6 days a year at Minneapolis and 19 days a year in Fukuoka. I’m not sure what the “replenishment” rate was. Let’s calculate for two possible rates: 2.5 g K m-2 and 5 g K m-2 (0.5 and 1 lb K/1000 ft2).
In an average year at Minneapolis, adding a half pound of K after each 1 inch rain event would add an additional 3 pounds of K per 1000 ft2; at the 1 pound rate it would be 6 pounds of K. And in a place with rain like Fukuoka, it would be an additional 48 g or 96 g K m-2 (9.5 or 19 lbs K/1000 ft2).
When comparing these amounts of K to the amount the grass will use, it is apparent that the quantity added as a replenishment is, depending on rainfall, from 2 to 13 times more than the grass can use. One wouldn’t think of overapplying N to such a degree, or overapplying water to that extent. Since there is no evidence that overapplying K provides any benefit to the turf, I would not worry about adding K after heavy rain.